Increasing demand for computational resources in the 5G and Beyond

As 5G networks evolve, RAN processing power is emerging as a critical resource. This demand is fueled by three primary drivers that will place the greatest strain on the network.
1- Radio Units
Modern radios have evolved to handle the relentless demand for higher speeds and performance. This is clearly seen in the progression from 2x2, 4x4, and 8x8 transceiver configurations to the advanced 64-transceiver arrays required for 5G Massive MIMO and its massive beamforming capabilities.
2- Channel Bandwidth
To meet the escalating capacity demands of emerging use cases, there has been a substantial expansion in available spectrum bandwidth—rising from 20 MHz in the low band for 4G, to 100 MHz in the mid-band and up to 800 MHz in the high band for 5G deployments.
3- Low Latency Requirements
The time transmission interval (TTI)—the critical processing loop within which the scheduler must operate—has significantly decreased with each successive generation of mobile networks. In 4G, TTI stood at 1 millisecond on the low band. In 5G, it has been reduced to 0.5 milliseconds on the mid-band and as low as 0.125 milliseconds on the high band. This reduction is a key enabler of advanced 5G use cases, including ultra-reliable low-latency communications (URLLC) for mission-critical applications, as well as enhanced mobile broadband (eMBB) scenarios such as immersive gaming.
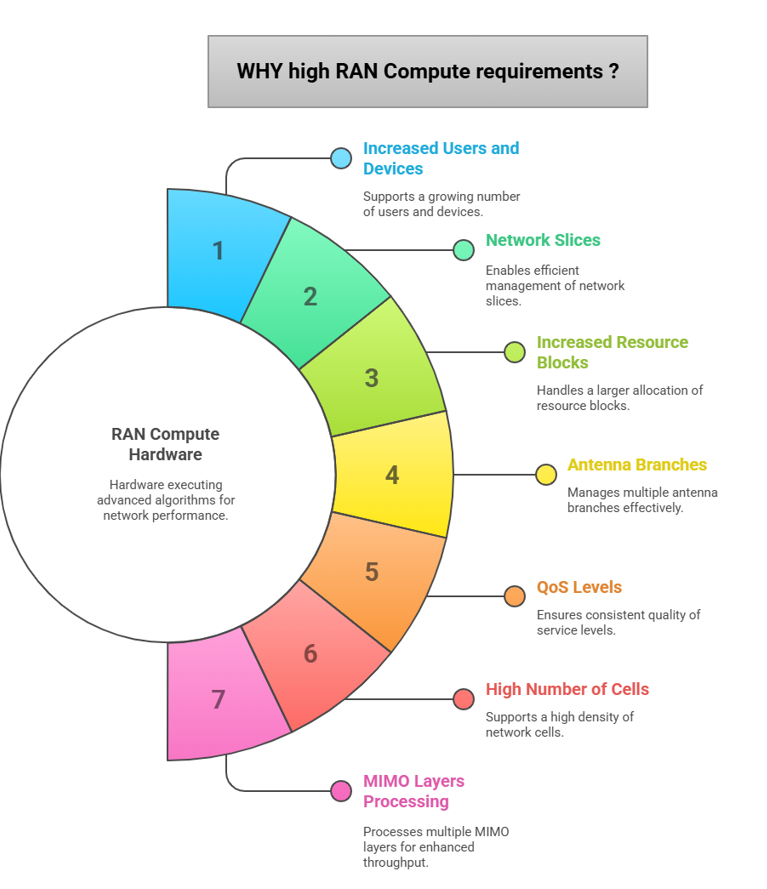
WHY RAN Processing Requirement is increasing?
Delivering best-in-class network performance in the future will present significant processing challenges. To ensure a consistently high-quality user experience, RAN Compute hardware must be capable of executing advanced algorithms for
1- Increased users and devices
2- Network slices
3- Increased resource blocks
4- Antenna branches
5- QoS levels
6- High number of cells
7- MIMO layers processing
And all this processing needs to be completed without fail within down to 0.0001 seconds!
Next-Gen RAN Compute: NVIDIA’s ARC-Compact
The new NVIDIA Compact Aerial RAN Computer (ARC-Compact) extends these capabilities to the edge, enabling AI-RAN at individual cell sites where space and power are at a premium, and RAN-centric workloads dominate. Together, they support both centralized and distributed AI-RAN.
ARC-Compact is purpose-built to enable distributed AI-RAN deployment models by integrating power efficiency, GPU-accelerated radio processing, and high-performance virtualized RAN (vRAN) capabilities. Leveraging the Arm ecosystem, it redefines traditional cell sites—transforming them into compact, multifunctional hubs for both 5G and AI workloads. The solution is optimized to address the physical and operational constraints of cell sites, delivering maximum capacity within the limits of power, space, and thermal budgets—while also adhering to stringent form factor requirements.
ARC-Compact supports a unified, software-defined architecture across both centralized (C-RAN) and distributed (D-RAN) deployments. It is designed with future readiness in mind, allowing seamless software upgrades toward 6G. At its core is the NVIDIA Grace CPU Superchip (C1), equipped with 72 high-performance, power-efficient Arm Neoverse V2 cores. For radio and AI workload acceleration, a PCIe plug-in card featuring the NVIDIA L4 Tensor Core GPU is integrated. High-speed connectivity is enabled via the NVIDIA ConnectX-7 network interface card (NIC), offering advanced Ethernet capabilities.
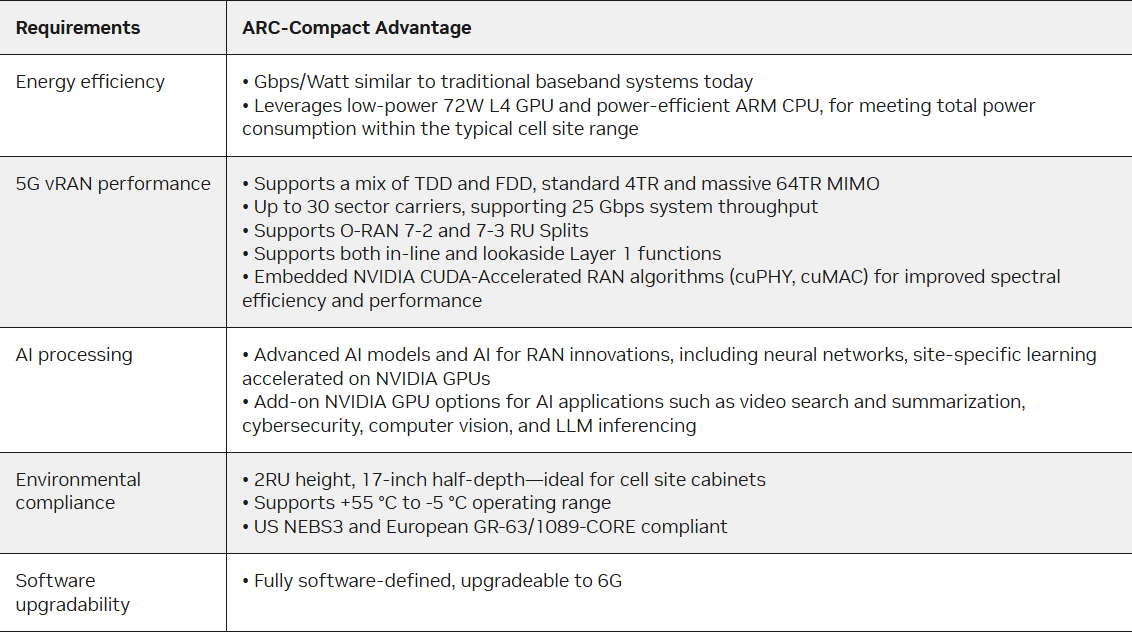
According to internal NVIDIA benchmarks, ARC-Compact meets the critical performance, power, and scalability requirements for distributed AI-RAN environments, as detailed in Table 1.

ARC-Compact adoption and availability
- NVIDIA ARC-Compact is anticipated to become available through a diverse set of OEM and ODM partners—including Foxconn, Lanner, Quanta Cloud Technology, and Supermicro—with whom Nvidia is actively co-developing Grace CPU Superchip C1–based systems. These systems are expected to be offered in a range of configurations tailored to support emerging telecom use cases, particularly distributed AI-RAN deployments, by the end of the year.
- The joint AI-RAN Innovation Center, announced during T-Mobile’s Capital Markets Day, has played a pivotal role in advancing ARC-Compact development. The initiative has yielded critical insights into architectural requirements and solution readiness for distributed AI-RAN applications. These learnings are informing the next phase of our AI-RAN collaboration, serving as the foundation for a D-RAN reference architecture.
- Vodafone is extending its strategic collaboration with NVIDIA by evaluating the ARM-based ARC-Compact platform for distributed AI-RAN use. This aligns with Vodafone’s Open RAN objectives to enhance performance and energy efficiency at the network edge, leveraging short-depth, edge-optimized servers for distributed compute workloads.
- As part of an early access program, Nokia has received initial seed systems of NVIDIA ARC-Compact and is testing its 5G Cloud RAN software stack on the platform. Early benchmarking results indicate strong alignment between ARC-Compact capabilities and the performance demands of distributed RAN scenarios—further deepening the ongoing Nokia-NVIDIA partnership in AI-driven RAN innovation.
- Samsung is expanding its collaboration with NVIDIA to integrate ARC-Compact into its 5G virtualized RAN (vRAN) portfolio. Building on a successful proof-of-concept last year that demonstrated seamless interoperability between Samsung’s vRAN software and NVIDIA L4 GPUs—with measurable gains in network performance and efficiency—Samsung is now evaluating ARC-Compact platforms incorporating NVIDIA Grace C1 CPUs and L4 Tensor Core GPUs. The goal is to accelerate advanced AI/ML workloads and further optimize vRAN performance at scale.
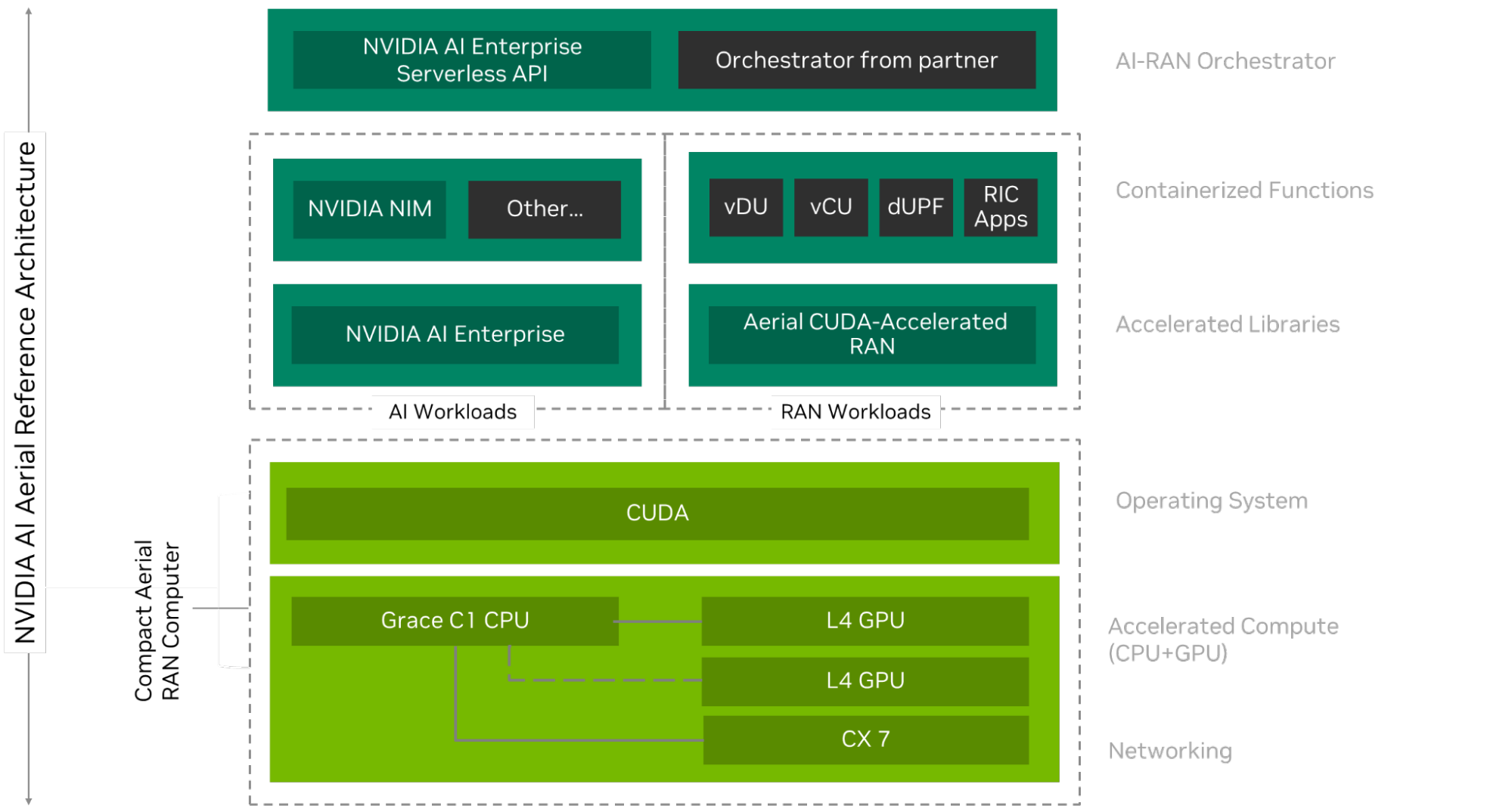
ARC-Compact is designed to efficiently process 5G vRAN and AI workloads, leveraging the following hardware and software components.
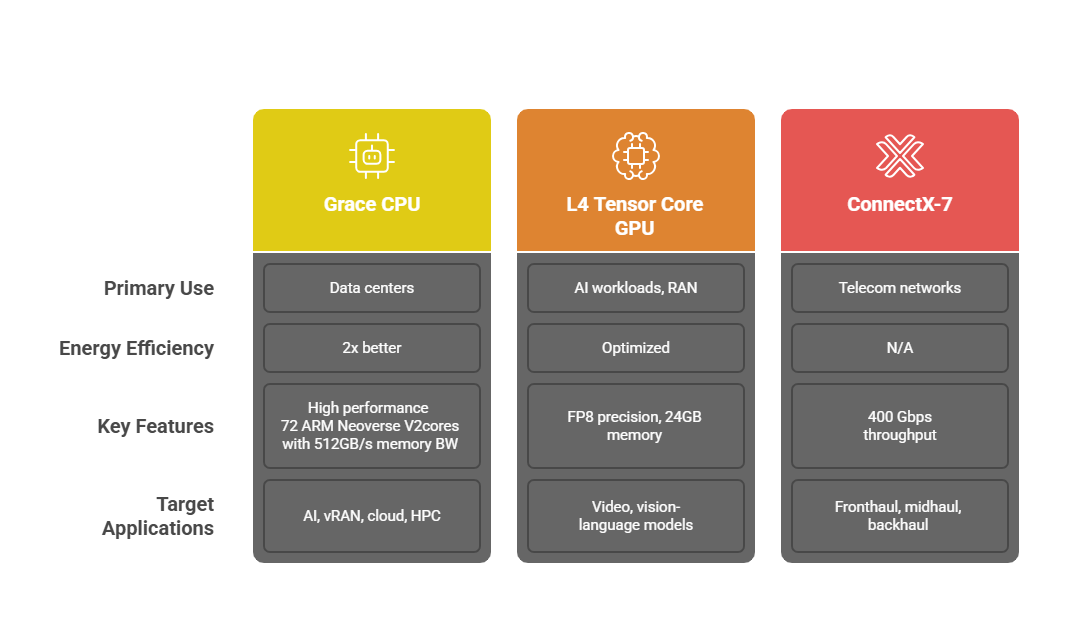
NVIDIA Grace CPU
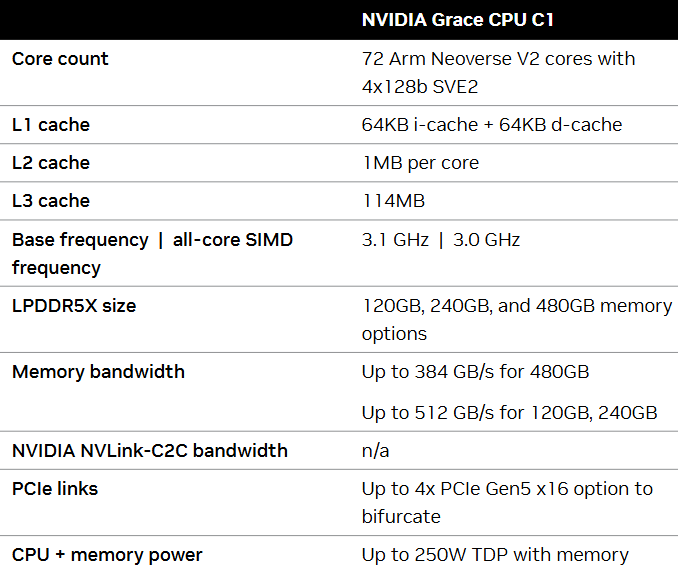
The Grace CPU is designed for modern data centers running AI, vRAN, cloud, edge, and high-performance computing applications. It provides 2x the energy efficiency of today’s leading server processors. Below are the Grace CPU C1 specifications.
NVIDIA L4 Tensor Core GPU
The NVIDIA L4 Tensor Core GPU, delivered as a PCIe plug-in card, offers a cost-effective and energy-efficient platform optimized for high-throughput, low-latency AI workloads and RAN (Radio Access Network) acceleration. With support for FP8 precision and 24 GB of GPU memory, the L4 delivers up to 485 teraFLOPS of AI performance—making it well-suited for edge AI use cases such as video search, summarization, and vision-language models. It also supports compute-intensive RAN functions, including Layer 1 processing and select Layer 2 tasks like scheduling. Engineered for deployment in constrained environments, the L4 provides up to 120x higher AI video performance compared to CPU-based alternatives, all within a compact, low-profile form factor and a 72W thermal design power (TDP) envelope.
NVIDIA ConnectX-7
NVIDIA’s ConnectX-7 delivers ultra-high-speed, low-latency Ethernet connectivity designed to meet the evolving demands of telecom networks across fronthaul, midhaul, and backhaul segments. With support for up to four ports and an aggregate throughput of up to 400 Gbps, it provides robust scalability for data-intensive workloads. Purpose-built for next-generation infrastructure, ConnectX-7 enables hardware-accelerated networking, storage, security, and manageability at data center scale. Key capabilities include in-line hardware acceleration for Transport Layer Security (TLS), IP Security (IPsec), and MAC Security (MACsec), as well as optimized routing for AI and machine learning traffic—making it a foundational enabler for advanced 5G and AI-driven telecom architectures.
Configuration Flexibility:
The system architecture offers flexible configuration options to accommodate a wide range of AI-RAN use cases, including:
- RAN-centric (RAN-only): This is anticipated to be the dominant deployment model in distributed environments. It operates efficiently with a single Grace C1 CPU paired with an L4 GPU, optimized exclusively for RAN workloads.
- AI-centric: In this configuration, the Grace CPU handles RAN functions (e.g., FDD), while the L4 GPU is dedicated to AI or visual processing tasks, enabling parallel AI-driven applications alongside RAN operations.
- RAN and AI-centric: Designed for more demanding scenarios, this setup incorporates an additional L4 GPU for AI or visual processing, while simultaneously supporting advanced RAN workloads using the primary Grace C1 CPU and L4 GPU.



Member discussion